

【论文阅读笔记】Deep Learning Image Steganalysis
发布于 2021-12-01 16:40 ,所属分类:知识学习综合资讯
Introduction
Preliminaries
1. The Framework of Prevailing Image Steganalysis Methods
2. Convolutional Neural Network Architecture
The Proposed Convolutional Neural Network For Steganalysis
Experiment
Conclusion
Deep Learning Hierarchical Representations for Image Steganalysis
几天要看的这篇论文是多媒体信息隐藏课程分配到的presentation。我觉得可以结合前几天VCC讲座中提到的对深度神经网络的理解中Representation的讲述,重点讨论里面这个representation。
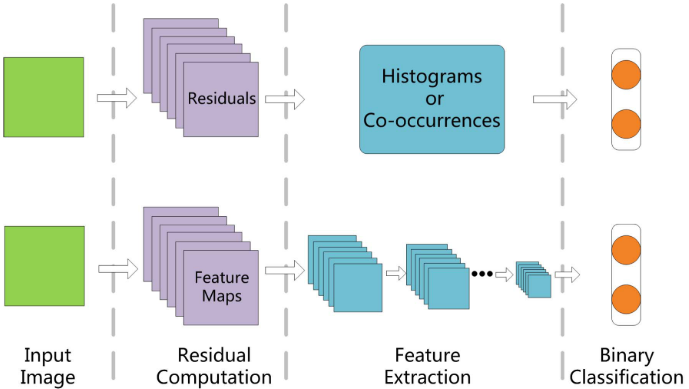
目前(指2017年),较为流行的信息隐藏分析的detector主要有以下三个步骤:
残差计算 residual computation 特征提取 feature extraction 二分类 binary classification
因此可以将steganlysis理解为一个二分类问题,也即判断一张图片有没有嵌入内容。在通常的CV任务中,图片的类型千奇百怪,提取的特征随着问题的不同也各有不同。其中,设计的重点就在于特征提取的特征该如何设计。如人脸的68个关键点坐标、如纹理的重复颜色几个结构、或者一定规则形状颜色变化等等,这也可以称为图像的representation。
考虑到隐写分析问题与传统的CV问题的相似性,作者提出可以用在CV领域表现优异的CNN来替换原本的隐写分析方法的一些步骤。当然,论文提出的网络架构是基于CNN基础上做了一定的修改。首先是网络的初始化策略,论文选择采用在SRM方法中用于计算残差图的high-pass filter,然后采用truncated linear unit作为激活函数,以便更好捕捉具有很低的SNR的嵌入信息结构。通过结合信道选择的知识,论文提出的方法比前有的深度学习隐写分析方法和传统方法SRM等都更有效。
Introduction
Image steganography is the science and art to conceal secret messages in the images through slightly modifying the pixel values or DCT coefficients.
信息隐藏对抗中主要有两个重点研究内容:Steganographic,Steganalysis。前者主要研究不着痕迹地将秘密信息嵌入图像中,而后者则研究如何判断一种图片是否经过了隐写信息嵌入。二者类似于生成对抗网络中的Generator与Discriminator,彼此对立统一,共同发展。
用styleGan举个例子,现阶段styleGan已经能够产生高度真实的人脸,对人而言,已经很难区别真实的自然人脸和styleGan生成出的人脸图像。styleGan2很好地解决了StyleGan1中出现的水泡问题,也让人脸图像的真实程度更上一层。但对现阶段人脸图像生成而言,只要产生的人脸图像足够骗过人就足够。而信息隐写的目标则是骗过专门的detector。


当前的信息隐写的技术绝大多数基于内容自适应隐写,也就是主要在高频信息或者边界处嵌入信息,尽力避免改变平滑处的图像,因为这样会更加明显。比如在一片255的像素中突然出现一个254,这可能会让detector检测的可能性直接拉满。现有的空域隐写技术如HUGO、WOW、S-NNIWARD都采用了这种方式。
随着信息隐写技术的发展,与之相对应的隐写分析方法也在不断改进。当前空域的state-of the art是SRM以及它的几个变种(Variant)。很多方法都使用select channel来改进SRM。当前最好的隐写算法都是基于ML和特征提取的方法,pipeline大致就是计算残差、提取特征然后二分类。当前最好的feature sets是SRM的共生矩阵(co-occurrence matrix)。从隐写分析的角度出发,为更全面地获取图像的完全信息,高维的representation是不可避免的。另外,现阶段的隐写特征都是启发式设计,特征提取的pipeline是独立优化的。
CNN一个重要的特性就是能够提取复杂的数据特征,VGG中,浅层可提取简单的几何形状,高层则提取较为复杂的纹理颜色特征。这是一种自然的分层次特征提取,也即论文标题的Hierarchical Representation。这种特性也使得CNN能够处理各种各样的CV任务,也能避免复杂的设计feature工作。前人的一些工作也证明了设计良好的CNN在隐写分析方面有比肩SRM性能。
在这篇论文中,作者同样提出了一种基于有监督CNN的隐写算法,作者提到论文提出的CNN有几个prominent characteristics:
将网络的第一层用于处理残差计算。使用SRM的30个filters来初始化网络权重,对应30个feature map,还能加速网络的收敛。 用截断线性单元(TLU)替代一部分ReLU激活函数。隐写是将一部分非常低SNR的信号嵌入到原图中。TLU的存在会让网络适应这种嵌入信号的细微分布,让网络更快学到high-pass filter。 使用selection channel
Preliminaries
1. The Framework of Prevailing Image Steganalysis Methods
还是说那三步,残差计算,特征提取,二分类
Noise Residual Computation
由于隐写是给图片添加很轻微的改动,因此自然处理残差比起处理原图的像素值要有效得多。给定一张test image




![[Android] 全套毕业论文写作指导 android电子市场(搭建环境+Galaxy S2模拟器全套+论文+代码+SVN)](https://static.kouhao8.com/sucaidashi/xkbb/41b11495e23c9df422ea269815e8a1ec.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)














![【衡水中学高考状元笔记】李曼茜5科手写笔记[百度网盘分享]](https://static.kouhao8.com/cunchu/cunchu7/2023-05-18/UpFile/defaultuploadfile/230430ml/187-1.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)


相关资源