

当脑机接口遇上机器学习:周志华《机器学习》读书笔记之模型评估
发布于 2021-04-26 05:40 ,所属分类:知识学习综合资讯

我们,了解脑机接口最新进展


作者/小时,老周
编辑/小时

Day 2
经验误差与过拟合
误差error=样本的真实输出-学习器的实际预测输出
学习器在训练集上的误差是训练误差,在新样本上的误差为泛化误差。我们希望泛化误差达到最小。
训练误差过大和过小都不好,过小的话会导致过拟合;过大会导致欠拟合。
Note:
机器学习中的过拟合与N/NP问题:
机器学习面临的问题通常是NP-hard甚至更难,而有效的学习算法必然是在多项式时间内运行完成,若可彻底避免过拟合,则通过经验误差最小化就能获最优解,这就意味着我们构造性地证明了“P=NP”,因此,只要相信“P≠NP”,过拟合就不可避免。
P/NP的定义:
P集合:在多项式时间内可以找出解的决策性问题的集合。
NP集合:在多项式时间内可以验证解是否正确的决策性问题的集合。
直白地讲,
P集合:可以很快求解的问题。
NP集合:可以很快验证给定答案是否正确的问题。
NP-hard集合:至少比任何NP问题一样难的问题。
NP-complete集合:同时满足两个条件:(1)该问题是一个NP问题;(2)所有NP问题可以归约为该问题。
模型的评估:如何得到测试集和训练集?
模型选择:选用哪一个学习算法,使用哪一种参数配置,使得泛化误差达到最小。
如何进行模型评估和选择?
通过实验测试来对学习器的泛化误差进行评估,从而进行选择。
所以,需要一个测试集来测试学习器对新样本的判别能力,然后以测试集上的测试误差作为泛化误差的近似。
测试集应尽可能与训练集互斥。达到举一反三的目的。
在数据集中得到测试集和训练集的三个方法:
留出法(hold-out)
直接将数据集D划分为两个互斥的集合——S(训练集)和T(测试集),
在S上训练出模型后,用T来评估测试误差,作为对泛化误差的估计。
S和T的划分要尽可能保持数据分布的一致性。通常采用分层采样的方法(stratified sampling)。
划分时可能存在多种划分方式。所以单次使用留出法得到结果不可靠,要进行多次随机划分、重复进行实验评估后取平均值作为留出法的评估结果。
划分多少S,多少T呢?常见的做法是将大约2/3—4/5的样本用于训练,其余用于测试。
交叉验证法(cross validation)
这是最常用的方法。
先将数据集D划分为k个大小相同的互斥子集,要从D中通过分层采样得到。每次用k-1个子集的并集作为训练集,余下的那个子集作为测试集。这样会获得k组S/T,进行k次训练和测试,最终返回的结果是这k个测试结果的均值。
k最常用的取值是10,其他常用的k值有5、20.
如果D里有m个样本,而k=m,叫做留一法(leave-one-out)。这样每个子集里只包含一个样本。
留一法得到的结果比较准确,但是计算复杂度非常高。
自助法(bootstrapping sampling)
也叫可重复采样或者有放回的采样。
包含m个样本的数据集D,对它进行一定方法进行采样后得到D',方法是:每次随机从D中挑选一个样本,拷贝这个样本放入D',然后再将这个样本放回D中,这个样本在下次挑选时还可能被挑到。此过程重复执行m次,D'里就能获得m个样本。
在数据集较小、难以有效划分S/T时很有用。
对于不平衡的样本,也可用bootstrapping。
D里的一部分样本始终不会被采到的概率,取极限是0.368.
D'作为训练集,D\D'是测试集。
Note:
D\D':集合的减法(difference)。
如何计算集合的减法:

▲如何用python实现集合的减法
自助法产生的训练集会改变D的初始分布,会引入估计偏差。
数据集较小,难以有效划分S/T时,适合用自助法;
数据集较大足够时,适合用留出法和交叉验证法。
具体什么样的数据集是较小、足够的呢?
样本的数量至少是参数的数量×10,可以找到类似的依据。
参数调节和模型选择评估的联系,先后顺序是什么?
模型等价于算法,先选择一种算法,然后去写代码,用上面提到的三种方法划分S/T,再根据跑出来的结果调节参数。
模型的评估:性能度量
性能度量(performance measure):衡量模型泛化能力的评价标准。
回归任务常用的性能度量是均方误差(mean squared error)。
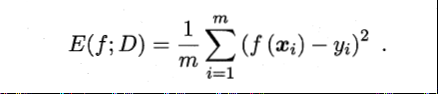
这里重点讲解分类任务中的性能度量。
错误率与精度——最常用
错误率:分类错误的样本数占样本总数的比例。
精度:是分类正确的样本数占样本总数的比例。
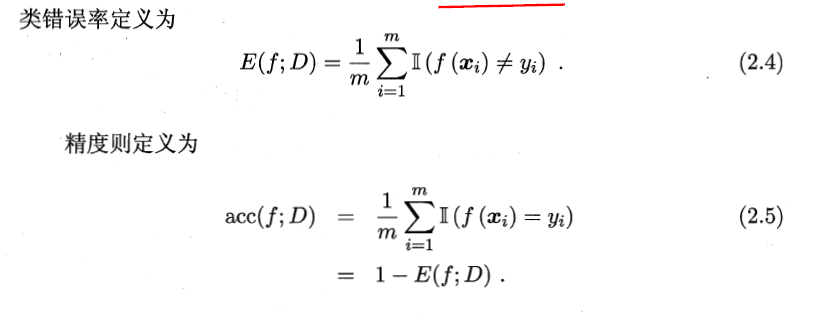
查准率/查全率(Precision/Recall)
查准率:挑出的西瓜中有多少是好瓜
查全率:所有好瓜里有多少被挑了出来
查准率高时,查全率往往比较低,二者相互矛盾。
用P-R曲线来表现查准率和查全率。
不同学习器,比较他们查准率和查全率性能优劣的方法:
(1)比较P-R曲线下面积的大小;
(2)平衡点(Break-evenPoint, BEP):查准率和查重率相等时的取值。平衡点越大,学习器性能越好;
(3)比平衡点更常用的指标是F1度量。
F1是一种调和平均数。

Note:
调和平均数(harmonicmean)又称倒数平均数,是总体各统计变量倒数的算术平均数的倒数。调和平均数是平均数的一种。但统计调和平均数,与数学调和平均数不同,它是变量倒数的算术平均数的倒数。由于它是根据变量的倒数计算的,所以又称倒数平均数。调和平均数也有简单调和平均数和加权调和平均数两种。主要是用来解决在无法掌握总体单位数(频数)的情况下,只有每组的变量值和相应的标志总量,而需要求得平均数的情况下使用的一种数据方法。
ROC和AUC
许多学习器是为测试样本产生一个实际的值或概率预测,然后将这个预测值与一个分类阙值(threshold)作比较,若大于阙值则分为正类,否则为反类。
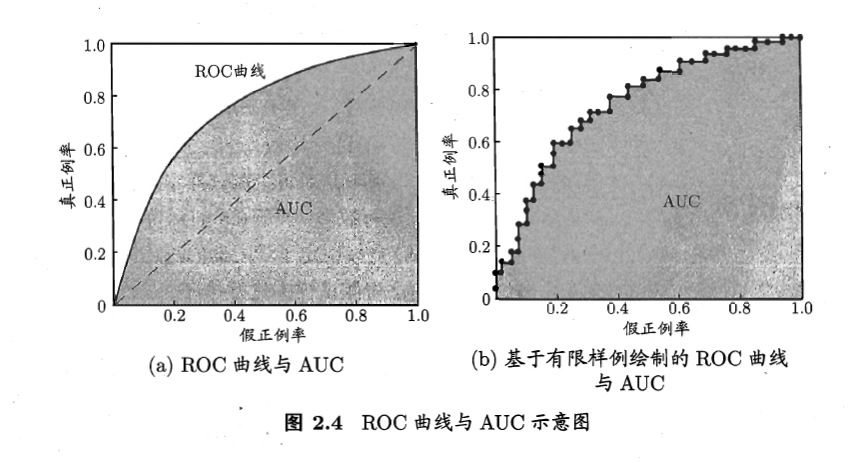
ROC曲线(Receiver Operating Characteristic):
根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出两个值——真正例率(True Positive Rate, TPR)和假正例率(False Positive Rate, FPR),以这两个值为横纵坐标,得到ROC曲线。

利用ROC曲线判断学习器性能优劣的方法:
比较ROC曲线下面的面积,AUC(Area Under ROC Curve)
排序质量和排序损失:
排序损失对应的是ROC曲线之上的面积,排序质量=1-排序损失
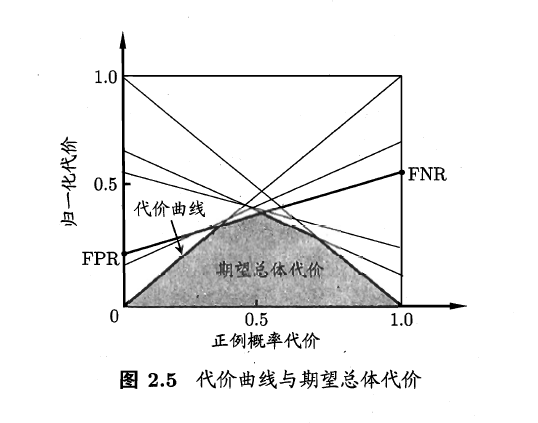
代价敏感错误率和代价曲线
不同类型的错误所造成的代价不一样,为权衡不同类型错误所造成的不同损失,可为错误赋予“非均等代价”(unequal cost)。
在非均等代价下,不能只是最小化错误次数,还要考虑最小化总体代价(total cost)。
可以用代价敏感错误率(cost-sensitive)来表示:
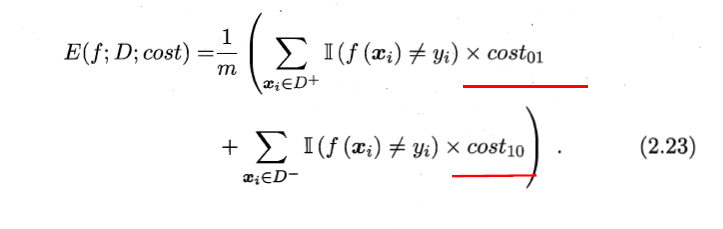
ROC曲线主要适用于均等代价情况,在非均等代价情况下,要用代价曲线(cost curve)来反映学习器的期望总体代价。
思考:如何与脑机接口结合
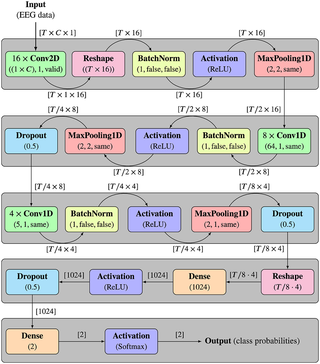
我们以一篇文章为例看看数据的准备和模型评估。
文章题目:
World’s fastest brain-computer interface: Combining EEG2Code with deep learning
主要内容:
主动和被动,是以用户为中心的观点产生的。主动式BCI用户必须主动与机器的通信,而在被动式BCI中,信息的传送无需用户进行任何额外的动作。
http://m.elecfans.com/article/778587.html
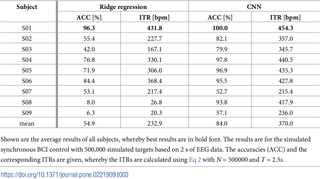
此外,它仅基于2秒的EEG数据就可以区分500,000种不同的视觉刺激,准确度最高可达100%。当使用该方法进行异步BCI(asynchronousself-paced BCI)拼写时,可以达到175bit/分钟的平均使用率,平均每分钟有35个无误的字母。
由于提出的方法提取的信息比以前最快的方法多三倍,因此文章认为EEG信号携带的信息要比一般普遍以为的要多。最后,文章观察到上限效应(aceiling effect),使得EEG中的信息含量超过BCI控制所需的信息含量,文章还讨论了BCI研究是否已达到非侵入式视觉BCI控制性的尽头了。
这里解释一下batch size,learning rate,epoch:
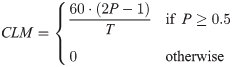



https://blog.csdn.net/weixin_42829639/article/details/89095196
https://baike.baidu.com/item/%E8%B0%83%E5%92%8C%E5%B9%B3%E5%9D%87%E6%95%B0/9661021?fr=aladdin
图源/CSDN、《机器学习》

作者介绍




扫ErWeiMa|我们


![[机器学习/深度学习] 机器学习算法&推荐系统算法精讲视频教程 机器学习高阶课程 机器学习视频+代码+PPT](https://static.kouhao8.com/sucaidashi/xkbb/b62e172d77c820f053a3f60c1d8bc042.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)


![[机器学习/深度学习] 深度学习最前沿技术 Kaggle案例实战课程 深度学习之Kaggle实战指南](https://static.kouhao8.com/sucaidashi/xkbb/8c854a271b0be2dd148fe341334e4c0e.png?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)
![[机器学习/深度学习] Matlab与机器学习进阶与提高班课程 炼数成金Matlab与机器学习13天入门实训课程](https://static.kouhao8.com/sucaidashi/xkbb/1658e78f4a490be019e84c51f74568ab.png?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)
![[机器学习/深度学习] 人工智能全新实战特训营-机器学习+人工智能+数据分析理论与实战教程 机器学习视频](https://static.kouhao8.com/sucaidashi/xkbb/9caec0936de2bd257a4f7b87f0dc83c3.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)





![[人工智能] 机器学习基石培训 台大讲师林轩田 机器学习基础入门培训视频教程 机器学习课程](https://static.kouhao8.com/sucaidashi/xkbb/0585ae2ea817269b2f2413c2697ede4e.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)
![[机器学习/深度学习] 炼数成金深度学习框架Tensorflow学习与应用课程 Tensorflow机器学习这套视频就够了](https://static.kouhao8.com/sucaidashi/xkbb/ffac0b07cbbe42a9be1ffe3f7ec7f409.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)



![[机器学习/深度学习] 最新机器学习超多项目实战 纯项目实战+音乐推荐系统+Pytorch+机器翻译+金融反欺诈等](https://static.kouhao8.com/sucaidashi/xkbb/3da1f01b4487d4c7524976ceb3991cc0.png?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)
![[机器学习/深度学习] 全球人工智能与机器学习技术大会 AICon人工智能专家团技](https://static.kouhao8.com/sucaidashi/xkbb/d7970e7abb546e6cbe9a4c45b030ed51.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)


![[机器学习/深度学习] 北风网人工智能全面系统学习课程 推荐系统+深度学习+机器学习三大阶段实战人工智能](https://static.kouhao8.com/sucaidashi/xkbb/73d1e5de58a3005bfe74a733a805e40c.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)




相关资源