

【论文导读】2021年论文导读第七期
发布于 2021-05-12 11:28 ,所属分类:论文学习资料大全


论文导读
2021年论文导读第七期(总第二十三期)
目 录
1 | Personal Fixations-Based Object Segmentation With Object Localization and Boundary Preservation |
2 | Cross-Domain Image Captioning via Cross-Modal Retrieval and Model Adaptation |
3 | Adaptively Learning Facial Expression Representation via C-F Labels and Distillation |
4 | Plant Disease Recognition: A Large-Scale Benchmark Dataset and a Visual Region and Loss Reweighting Approach |
5 | Convex and Compact Superpixels by Edge-Constrained Centroidal Power Diagram |
6 | Embedding Perspective Analysis Into Multi-Column Convolutional Neural Network for Crowd Counting |
7 | DASGIL: Domain Adaptation for Semantic and Geometric-Aware Image-Based Localization |
8 | Bidirectional Interaction Network for Person Re-Identification |

Personal Fixations-Based Object Segmentation With Object Localization and Boundary Preservation
利用对象定位与边界保持进行基于个性化注视点的对象分割
作者:李恭杨1,刘志*1,史冉2,胡政1,魏伟杰1,吴勇1,黄梦珂1,凌海滨3
单位:1上海大学,2南京理工大学,3纽约州立大学石溪分校
邮箱:ligongyang@shu.edu.cn; liuzhisjtu@163.com; rshi@njust.edu.cn; huzhen1995@shu.edu.cn; codename1995@shu.edu.cn; yong_wu@shu.edu.cn; huangmengke@shu.edu.cn; hling@cs.stonybrook.edu。
论文:https://ieeexplore.ieee.org/document/9298925
代码:https://github.com/MathLee/OLBPNet4PFOS
*为通讯作者
人眼注视点是一种极其灵活和方便的交互方式。其与点击、涂画和打框相比,大大提高了交互的效率。此外,注视点还与个体的性别、年龄、受教育程度等密切相关,这表明在一定程度上注视点是个体特性的一种体现。由此受到启发,我们在本文中基于个性化注视点探索交互式对象分割,并创建了首个个性化注视点交互式分割数据集PFOS和提出了基于对象定位与边界保持的注视对象分割方法。
问题阐述:如图1第一列所示,不同的个体观察一张图像会产生不同的注视点集。在本任务中,给定一张图像和个体的注视点密度图(将注视点经过高斯模糊后得到,如图1第二列所示),目标是分割出个体在观察过程中注视过的对象区域(如图1第三列所示)。因此,本任务的输入是图像和注视点密度图(或注视点),输出是注视对象区域的二值图。

图1 基于个性化注视点的交互式对象分割任务
PFOS数据集:本数据集是在著名的注视点预测数据集OSIE上改建而成的,共含有700张分辨率为800×600的图像。每张图像都由15个被试者观看过,并记录了每个被试者的注视点,由此对注视对象进行标注,获得二值的标注图。此数据集中的600张图像及其对应的9000张注视点图和二值标注图为训练集,余下的100张图像及其对应的1500张注视点图和二值标注图为测试集。
基于对象定位与边界保持的注视对象分割方法:注视点密度图携带着注视对象的位置信息,但是其中也含有大量噪声(落在背景区域的注视点),这给注视对象的分割带来了极大的干扰。为了解决这个问题,本文首先利用注视点密度图含有的位置信息对注视对象进行定位,而后利用图像中的注视对象区域有边界而背景区域无边界这一特性,基于边界信息对错误定位的背景区域进行滤除,从而得到准确的分割结果。
如图2所示,本文提出的分割网络包含特征提取、对象定位和预测三个部分。在对象定位部分,对象定位模块(OLM)利用并行的带有不同扩张率的扩张卷积,挖掘不同感受野下的位置信息以得到位置响应图。随后,位置响应图将作为权重,对VGG网络从图像中提取到的特征图进行加权,以突显特征图中的注视对象区域。我们还在此模块中施加监督以提高对象定位的准确性。在预测部分,边界保护模块(BPM)提取边界信息,并利用边界信息对对象定位模块输出特征图中的错误定位区域(落有注视点的背景区域)进行矫正。此外,我们还在预测部分构建了对象分割和边界预测两个分支以提高对象分割的准确性。
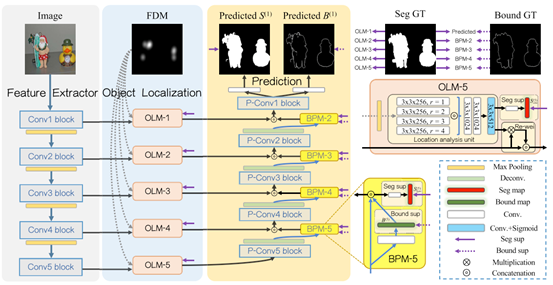
图2 基于对象定位与边界保持的分割网络框架图
如表1所示,实验结果表明在PFOS数据集上,本文提出的方法比已有的5种类型共计17种方法具有更高的分割精度。
表1 与已有的17种方法在PFOS数据集上的分割性能比较


02
Cross-Domain Image Captioning via Cross-Modal Retrieval and Model Adaptation
作者:赵文天1,吴心筱1,罗杰波2
单位:1北京理工大学,2罗彻斯特大学
邮箱:wuxinxiao@bit.edu.cn
论文:https://ieeexplore.ieee.org/document/9292444
代码:https://github.com/wentian-zhao/cross-domain
一般的图像描述(image captioning)方法需要大量的训练数据,包括图像及相应的自然语言标注。然而,面对新的领域,为大量图像标注自然语言是一项费时费力的工作。因此,本文提出利用现有的标注数据(源域),训练新领域(目标域)的图像描述模型,即跨域图像描述。在该任务中,源域通常包含大规模的图像和对应的标注语句。目标域规模相对较小,包含未标注图像以及与图像无关的语料。同时,源域与目标域中的图像和语句均存在差异。图1以MSCOCO数据集和Oxford-102数据集为例,展示了源域与目标域之间的差异。其中,MSCOCO数据集为源域,描述了人以及物体之间的关系,而目标域CUB-200数据集主要描述花的形状特征。
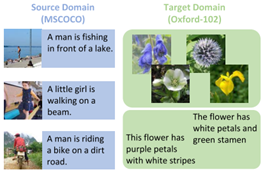
图1 跨域图像描述中的源域与目标域示例
本文提出一种跨域图像描述方法,通过跨模态检索模型找出目标域上最相似的“图像-语句”对,解决因目标域图像未标注而引起的图像描述模型无法迁移问题。此外,为了减少源域与目标域之间的语句分布差异,我们提出基于LSTM的自适应语言生成模型,使得源域语言生成模型有效迁移至目标域。如图2所示,本文提出的方法包括跨模态检索模型和图像描述模型。训练过程包括预训练阶段和微调阶段。预训练阶段使用源域中的数据对两个模型进行预训练。在微调阶段,通过迭代算法找出目标域中图像与语句之间可能的配对关系,即伪“图像-语句”对。在每次迭代中,通过检索得到相似程度最高的图像和语句,并使用这些图像以及语句,对跨模态检索模型进行微调,如图2左半部分所示。本文使用最后一次迭代得到的伪“图像-语句”对进行图像描述模型的迁移训练。在基于LSTM的自适应语言生成模型中,我们使用两组参数分别学习源域以及目标域中与语言模式相关的知识,并能够动态地在两组参数之间进行切换,如图2右半部分所示。
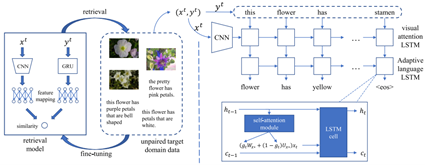
图2 本文方法
本文使用MSCOCO数据集作为源域,使用Flickr30k,CUB-200,Oxford-102以及TGIF四个数据集分别作为目标域进行了实验。本文提出的方法在所有的目标域上都取得了最好或与已有的方法相当的性能,验证了方法的有效性。图3展示了不同目标域上生成的句子,这些结果表明本文提出的方法能够较准确地描述图片的内容。图4为部分检索结果的示例,可以看出本文的检索模型能够在没有配对数据的目标域上找出具有相似语义的图片以及句子,从而准确地引导图像描述模型的迁移。
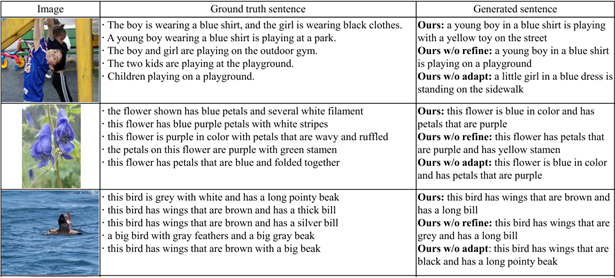
图3 在Flickr30k,Oxford-102以及CUB-200数据集上生成的部分句子

图4 Flickr30k数据集上的部分检索结果示例

03
Adaptively Learning Facial Expression Representation via C-F Labels and Distillation
基于粗-细标签和蒸馏的自适应人脸表情表征学习
作者:李航宇1,王楠楠1*,丁鑫棚1,杨曦1,高新波2
单位:1西安电子科技大学,2重庆邮电大学
邮箱:hangyuli.xidian@gmail.com; nnwang@xidian.edu.cn
论文:https://ieeexplore.ieee.org/document/9321757
人脸表情是人际交往中一种重要的情感表达方式。人脸表情识别(facial expression recognition, FER)是指利用计算机提取被检测人脸的特征,使计算机能够理解人脑思维产生的表情状态,并及时响应人们的需求。目前,研究人员已经开展了大量的人脸表情识别工作,并取得了不错的性能表现。本文回顾了近年人脸表情识别领域的研究进展,从中发现影响FER算法性能的根本原因是大模型在识别高度相似的人脸表情时,没有考虑类别不平衡数据影响下的人类经验。具体为:其一,从互联网上收集的人脸表情数据差异小、难以被标注,很难获得足够的负面表情(如厌恶、恐惧和愤怒),使得真实场景下FER数据集的标签分布高度不平衡;其二,许多表情需要在面部区域进行相似的肌肉运动,没有明显的差异化特征。卷积神经网络提取相似表情的表征能力较弱,很难学习到重要的表情信息;其三,深度人脸表情识别模型计算成本高,内存占用大,阻碍其在资源受限设备上的部署。
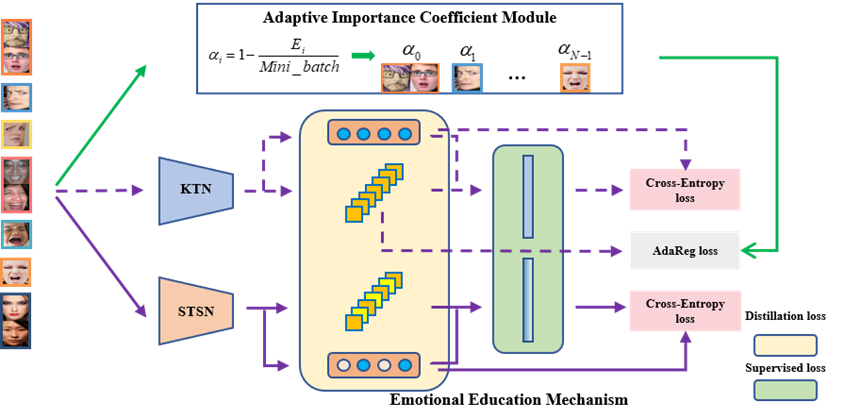
图1基于粗-细标签和蒸馏的自适应人脸表情表征学习方法框图
如图1,本文通过三个步骤设计了完整的人脸表情识别技术。首先,该方法提出了一种自适应正则损失,以监督卷积神经网络学习类别不平衡的表情表征。其次,粗-细标签策略为人脸表情识别模型提供了参考,使模型能够由易到难地区分人脸表情。具体来说,在现有标签(快乐、惊喜、悲伤、愤怒、厌恶、恐惧和中性,即细标签)的基础上,重新定义粗标签(积极、消极、中性和惊喜)作为新的辅助监督信号,以解决高相似度的人脸表情识别问题,避免了搜索表情区域的代价。第三,基于上述两个步骤,可以实现性能优越的FER大模型。为了实际部署人脸表情识别模型,释放轻量级模型的潜力,该方法提出了一种情感教育机制,即预训练教师网络监督并指导学生网络,且后者能够基于标签信息自主学习表情特征。该框架为实现智能表情识别系统提供了一种新方法,主要贡献在于:(1)自适应地获取表情表征的重要性系数,有效地将类别不平衡与高维特征分布相结合;(2)重新定义表情类别,为FER网络提供新思路,减少相似度的影响;(3)情感教育机制首次利用知识蒸馏帮助监督表情特征学习。
实验部分,本文在RAF-DB、AffectNet和FERPlus三个真实场景下的FER数据集上进行了详细实验分析。结果表明,所提方法优于已有的SOTA算法,消除了表情样本不平衡、高相似性的不利影响,具有更高的识别精度,有效地提升视觉情感认知的能力。

04
Plant Disease Recognition: A Large-Scale Benchmark Dataset and a Visual Region and Loss Reweighting Approach
作者:刘鑫达1,闵巍庆2,梅舒欢3,王莉莉*1,蒋树强2
单位:1北京航空航天大学,2中国科学院计算技术研究所,3北京普惠三农科技有限公司
邮箱:
liuxinda@buaa.edu.cn, minweiqing@ict.ac.cn, long8622416@163.com,
wanglily@buaa.edu.cn, sqjiang@ict.ac.cn.
论文:https://ieeexplore.ieee.org/document/9325065
每年,全球高达40%的粮食作物因病虫害而遭受损失。这导致每年的农业贸易损失超过2200亿美元,数以百万计的人们陷入饥饿。近年来图像处理技术特别是深度学习的发展为病虫害识别提供了新的可行方案,但由于缺乏系统分析和足够的数据量支撑,研究并没有形成应有的规模。本文系统分析了在计算机视觉视角下的病害识别问题面临的挑战,收集了一个包含271类病害、超过22万张图像的数据集,如图1所示。

图1
基于此数据集,我们通过对视觉区域和损失进行加权来强调病态部分,从而解决植物病害识别问题,如图2所示。 我们首先根据这些图像块的聚类分布计算所有图像块的权重,以表示每个图像块的判别能力。 然后,我们在弱监督训练期间为每个图像块-标签对的损失分配权重,用以增强植物患病部位的特征学习。 最后,我们从经过损失函数重加权训练所得的网络中提取图像块特征,并利用LSTM网络将加权后的图像块特征序列编码成一个全面的特征表示。 我们提出的方法从图像和特征两个层次对强化植物患病位置的影响力,同时通过拆分和重组兼顾全局和局部信息。我们在提出的数据集和另一个公共数据集上进行了大量评估证明该方法的优势。我们希望这项研究将进一步推动图像处理领域中植物病害识别的进程。
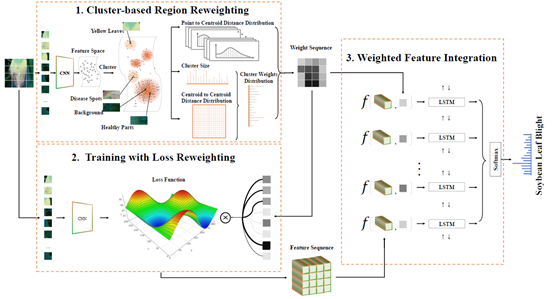
图2

05
Convex and Compact Superpixels by Edge-Constrained Centroidal Power Diagram
基于边界约束质心power图的规整凸超像素分割
作者:马东阳1,周元峰*1,辛士庆2,王文平3
单位:1山东大学软件学院,2山东大学计算机科学与技术学院,3香港大学计算机科学系
邮箱:yfzhou@sdu.edu.cn
论文:
https://ieeexplore.ieee.org/document/9305971
代码:
https://github.com/madongyang-stack/ECCPD
超像素分割是一项重要的图像预处理技术,在许多计算机视觉领域都有重要应用。边界贴合性和形状规整性是衡量超像素分割效果的两个重要指标,但是这两者之间往往很难达到一个很好的权衡。凸超像素具有较好的规整性,但很难达到理想的边界贴合性。目前已有的超像素算法大多是基于聚类或者是基于图的方法,这些方法生成的超像素的边界不光滑且是锯齿状的,这限制了这些超像素方法在一些计算机视觉任务的应用,比如图像压缩和物体多边形轮廓提取等。为了探索一种新颖的超像素算法来打破这些限制,本文没有沿用基于聚类或者基于图的方法,而是巧妙的使用了计算几何工具power图,设计了一种基于边界约束质心power图(Edge-Constrained Centroidal Power Diagram, ECCPD)的凸超像素算法。Power图是空间中具有权重的站点按一定规则生成的凸多边形的集合,可以将平面区域分割成凸多边形,不仅让凸超像素具有了良好的边界贴合性,同时大大降低了超像素的存储复杂度,将原有的离散存储方式变为矢量存储方式,仅需保存每个超像素对应的站点位置及权值即可。
本文提出的ECCPD凸超像素分割的算法框架如图一所示可以分成三部分:凸超像素初始化,算法交替优化求解和后处理。初始化阶段首先提取图像的边界,然后根据边界分布一些固定站点,根据这些站点生成初始power图。优化求解阶段交替优化站点的位置和权重,通过优化站点的位置使之移动到相应区域的质心可以使超像素更加规整,通过优化站点的权重使之控制超像的大小可以提高边界贴合性。后处理阶段主要是移动那些区域内有明显边界穿过的多边形的顶点提高分割准确性。
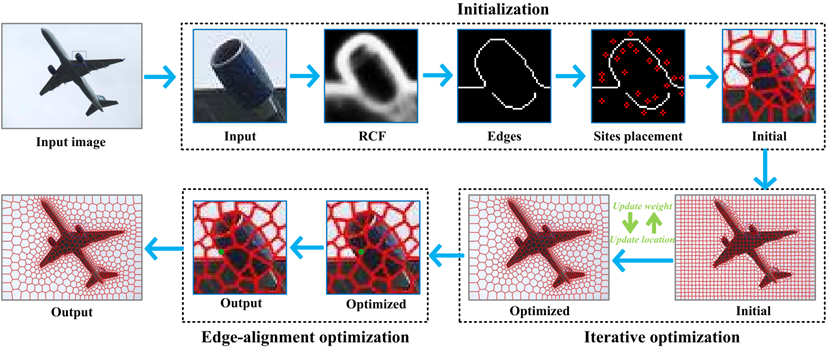
图一 ECCPD凸超像素算法框架
本文提出的ECCPD凸超像素方法在算法优化过程中充分考虑超像素的边界贴合性和规整性,提出了一系列改善方法,在规整性可以保持的情况下其生成的超像素的边界贴合性甚至超过了很多基于梯度和基于图的超像素算法。从图二可以看出ECCPD凸超像素方法可以很好的达到边界贴合性和规整性的一个权衡。图三给出了ECCPD算法部分结果的视觉效果,该方法通过控制相关参数可以生成尺寸相似的超像素和尺寸可控的超像素。
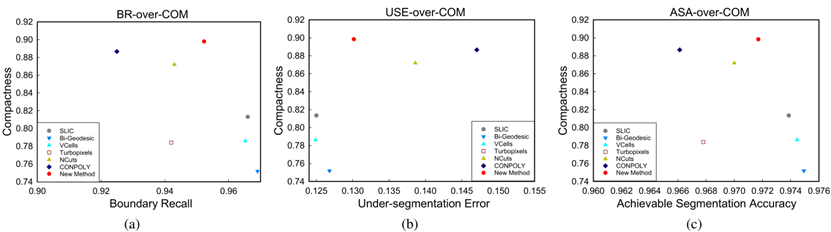
图二 在BSDS 500数据集上的定量比较实验结果

图三 本文算法部分结果的视觉效果。第一行:输入图像;第二行:尺寸相似的超像素;第三行:尺寸可控的超像素
相比于其他凸超像素分割方法,ECCPD算法无论是在形状规整性上还是在分割准确性上都体现出了优势。本文将该算法应用于图像压缩(图四)和物体多边形轮廓提取(图五)中,通过部分实验结果可以发现本文方法具有一定的优势。

图四 本文算法可应用于图像压缩,在该应用上部分实验结果与其他凸超像素方法的视觉比较

图五 本文算法可应用于物体多边形轮廓提取,在该应用上部分实验结果与其他凸超像素方法的视觉比较

06
Embedding Perspective Analysis Into Multi-Column Convolutional Neural Network for Crowd Counting
基于透视分析的多列卷积神经网络人群计数
作者:杨一帆1, 李国荣1,独大为2,黄庆明1,Nicu Sebe3
单位:1中国科学院大学计算机科学与技术学院,2美国纽约州立大学奥尔巴尼分校,3意大利特伦托特伦托大学
邮箱:yangyifan16@mails.ucas.ac.cn
论文:https://ieeexplore.ieee.org/document/9293174
视觉目标计数的两个关键挑战是任意的视角和较大的尺度差异。在大多数目标计数数据集中,每幅图像都有一个独特的视角和场景。研究者很难明确地获得视角信息。因此,一些视觉目标计数方法忽略了视角分析,而使用不同的感受野来适应不同的尺度。然而,多个感受野的有效性可能不突出,因为深度网络在图像上共享卷积核。另一方面,一些方法提供后处理模块,用预测的透视图平滑估计结果。然而,这些方法生成的真值透视图需要有额外的注释,并且预测的透视图具有很强的噪声。因此,用这些透视图平滑输出不可避免地会引入噪声。
如图1,我们提出了一个简单而有效的多行网络,它将视角分析方法与计数网络相结合。该方法显式地挖掘视角信息,并驱动计数网络对场景进行分析。具体而言,我们从估计的密度图中挖掘视角信息,并将连续透视空间量化为几个独立的透视场景。然后,我们将视角分析嵌入到具有循环连接的多行框架中。因此,该网络能有效地匹配不同尺度目标和不同感受野的分支。其次,我们让具有不同感受野的分支网络共享参数。该策略使得卷积核对不同尺度的目标都具备敏感度。此外,为了提高大感受野分支的计数精度,我们提出了一种变换空洞卷积。变换空洞卷积打破了深层网络固定的特征采样结构。此外,该算法不需要额外的参数和训练,并且偏移量被限制在局部区域,这是为拥挤场景独特设计的。
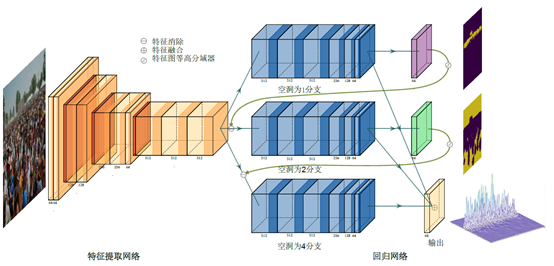
图1、蓝色的后端模块表示具有共享参数的卷积层,该卷积层具有不同的空洞采样率以获得不同的感受野。在蓝色模块之后连接的彩色卷积层表示分支的回归。虚线表示循环连接。
在图2 中,我们报告了从循环连接输出的量化透视场景。在每幅图像中,这些区域很好地分隔了不同透视场景中的目标。利用多分支结构解决尺度差异的优势也因循环连接而得以彰显。

07
DASGIL: Domain Adaptation for Semantic and Geometric-Aware Image-Based Localization
语义几何信息辅助的域自适应图像定位
作者:胡寒江1,乔志健1,程铭1,刘哲2,王贺升1*
单位:1上海交通大学自动化系智能机器人与机器视觉实验室,2英国剑桥大学计算机科学与技术系
联系邮箱: huhanjiang@sjtu.edu.cn, wanghesheng@sjtu.edu.cn
论文链接:https://ieeexplore.ieee.org/document/9296559
开源模型和代码:https://github.com/HanjiangHu/DASGIL
视觉定位在移动机器人和自动驾驶领域中扮演着至关重要的角色,特别是对于同时定位和建图(SLAM)系统而言,基于图像检索的视觉定位提供了低成本、高效准确的定位方法,成为视觉回环检测和重定位中的重要技术。然而在长期变化的复杂室外环境中,季节、天气、光照等因素严重影响了传统图像匹配和场景识别算法的准确性,为长期鲁棒运行的SLAM系统带来了巨大挑战。随着深度学习和计算机视觉的发展,卷积神经网络提取的深度特征可以充分挖掘场景中的几何和语义信息,对复杂环境有着较好的鲁棒性,极大地促进了单目深度预测、语义分割等视觉感知任务的发展。
该工作利用视觉感知中的丰富的几何信息和语义信息在同一个地点与变化环境无关的特性,提出了语义几何信息辅助的域自适应图像定位(Domain Adaptation for Semantic and Geometric-aware Image-based Localization, DASGIL),将融合了几何语义的特征用来辅助变化环境下的场景识别,大大提高了场景识别和视觉定位的准确率。但是由于真实环境中不同环境多种任务下人工标注真值的获取成本较高,该工作利用域自适应的方法在合成虚拟数据集上训练融合特征提取模型,并且通过对抗训练的方式消除了虚拟图像和真实图像的特征差异,从而实现了测试时模型在真实数据集上的泛化和迁移。
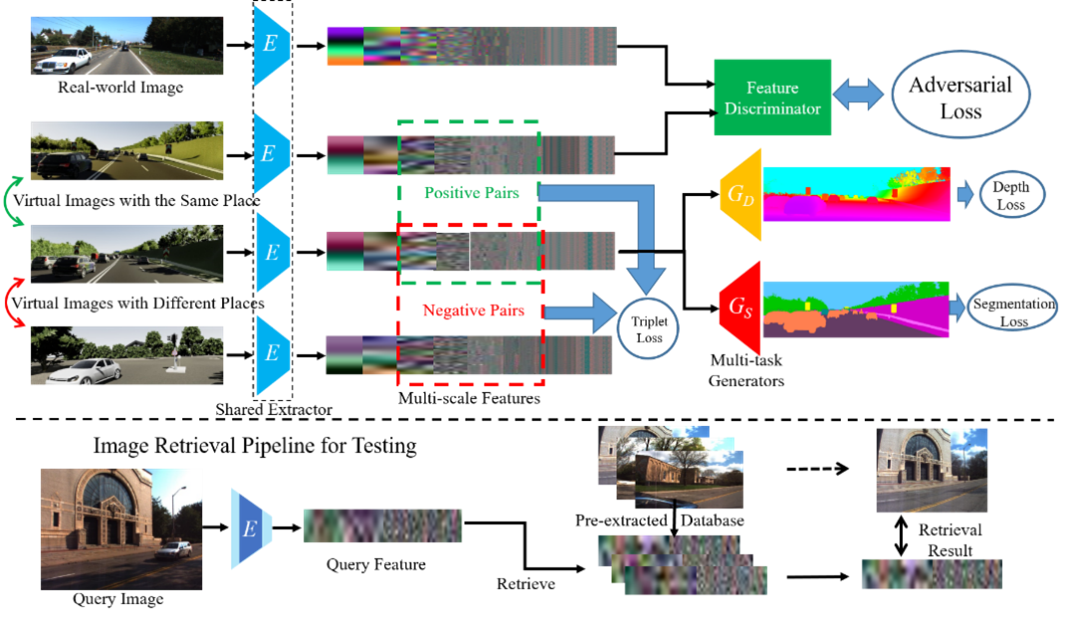
图1 语义几何信息辅助的域自适应图像定位方法架构和测试流程
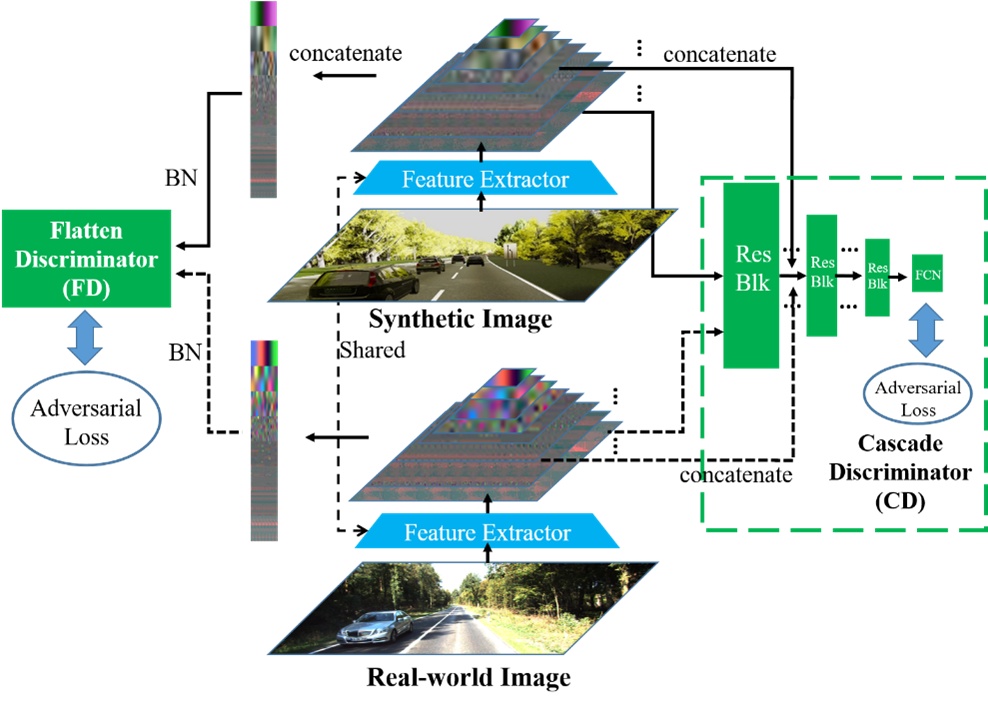
图2 扁平式判别器和级联式判别器结构图
图1展示了语义几何信息辅助的域自适应图像定位方法架构和测试流程。网络架构采用了采用一个编码器和二个解码器的深度预测和语义分割多任务学习架构,通过共享的融合特征提取器将从虚拟图像提取的几何信息和语义信息融合到多尺度潜在特征上,并通过多尺度三元损失函数完成了用于虚拟图像位置识别的度量学习。虚拟图像和真实图像的融合特征使用图二所示的扁平式判别器(Flatten Discriminator, FD)和级联式判别器(Cascade Discriminator, CD)通过对抗训练使得多层潜在特征服从相同的分布,从而完成从虚拟图像到真实图像的域自适应。

图3 虚拟图像,有域自适应的真实图像,没有域自适应的真实图像的定性对比
表1 不同区域下的实验结果
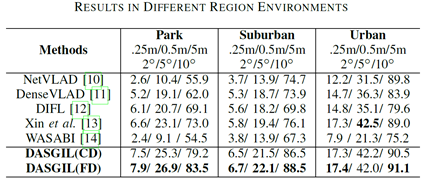
表2 不同植被下的实验结果
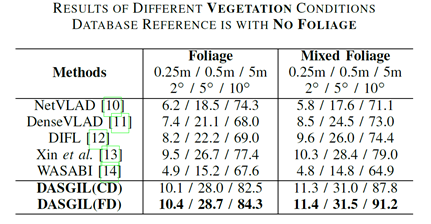
图3 不同天气下的实验结果
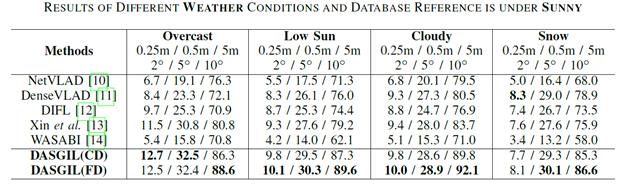
在实验中,该工作在Virtual KITTI 2虚拟数据集上有监督地训练了深度预测、语义分割以及度量学习模型,在KITTI真实数据集上进行了无监督的特征提取器对抗训练。图3展示了虚拟图像、有域自适应的真实图像以及没有域自适应的真实图像的定性对比,可以看出域自适应明显克服了真实和虚拟数据集的差异,深度预测、语义分割效果更好同时多尺度特征分布更加一致。之后在Extended CMU-Seasons数据集上完成了长期视觉定位的测试,表1,2,3分别展示了模型在不同区域、植被和天气情况下的实验结果,包含了(0.25m,2°),(0.5m,5°)和(5m,10°)三种精度下的定位准确率结果。可以看出我们的结果由于当前最好的基于检索的定位方法,实验结果可以在https://www.visuallocalization.net/benchmark上获得,开源代码和预训练模型可以在https://github.com/HanjiangHu/DASGIL上获得。

08
Bidirectional Interaction Network for Person Re-Identification
基于双向交互网络的行人再识别技术
作者:陈秀妹1,2,郑向涛1,卢孝强1
单位:1中国科学院西安光学精密机械研究所,2中国科学院大学
邮箱:chenxiumei17@mails.ucas.ac.cn, xiangtaoz@gmail.com,luxiaoqiang@opt.ac.cn
论文:https://ieeexplore.ieee.org/document/9321734
行人再识别旨在判断不同摄像头中行人的身份,从不同的图像中查找同一行人。由于摄像头的差异,行人图像受到视角、姿态、尺度、穿着和遮挡等因素的影响存在较大差异,因此,提取具有身份判别性的局部细节对于行人再识别至关重要,例如发型、体型、鞋子等。现有的方法利用人体部位定位技术来辅助学习人体局部细节的判别表示,然而,这需要繁琐的人体部位定位标注。我们提出一种基于深度学习的双向交互网络,利用多个卷积层的交互作用,在不需要人体部位定位的情况下提取出有效的局部细节。具体地,深度网络的卷积层特征反映了人体身体部位属性的响应,同时,不同层次的卷积层特征通常不同级别的信息:浅层特征更低级纹理等细节而深层特征更侧重高级语义信息。因此,我们提出双向交互网络,通过双向迭代交互的方式来获取不同卷积层特征的互补信息,从而增强对人体局部细节的判别表示。
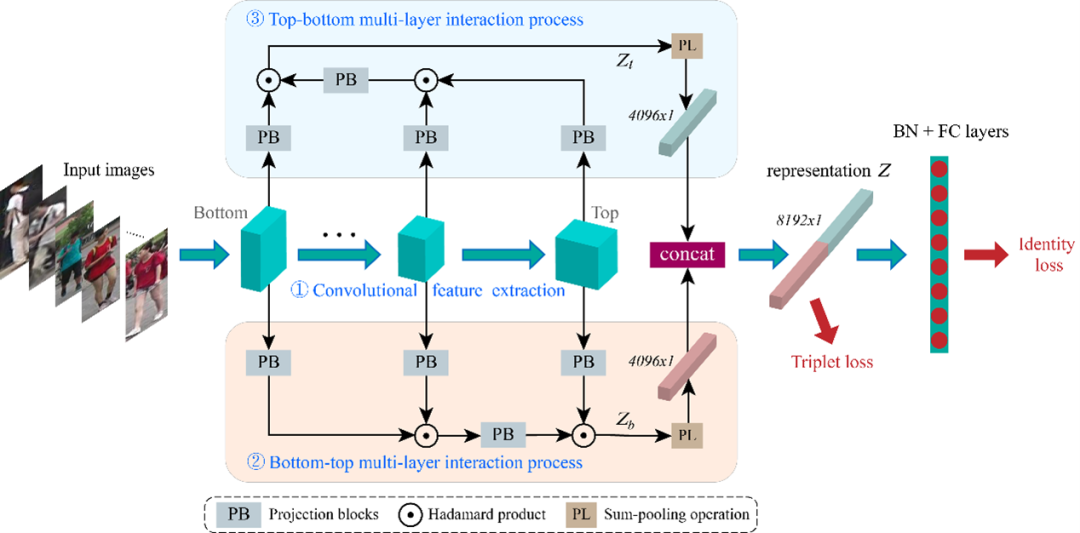
图1 面向行人再识别的双向交互网络框架
图1展示了所提出的双向交互网络框架,该网络由自浅而深(Bottom-top)和自深而浅(Top-bottom)两种多层交互过程构成。首先,将图像输入卷积神经网络提取不同层的卷积特征。其次,在自浅而深的多层交互过程中,将浅层的低响应特征逐级积累,避免交互过程中被深层的高响应特征完全抑制,从而有效保留局部细节的低级信息。然后,在自深而浅的多层交互过程中,将深层高响应特征逐级向下传递,突出局部细节的高级语义信息。最后,将两种交互特征进行整合生成行人身份的判别表示。
实验结果表明所提方法在多个公开数据集上均达到了先进的识别精度,例如在Market-1501上达到95.1% 的rank-1精度。图2展示了卷积层特征响应的可视化结果,可以看出:(1)不同卷积层响应区域不同,具有不同的属性;(2)两种交互特征都比未交互特征具有更紧凑的响应区域,说明交互过程可以忽略杂乱的背景,加强局部细节区域的响应程度;(3)两种交互特征具有不同的点。自浅而深的交互特征多个区域的响应,考虑多个局部细节信息;自深而浅的交互特征通常只有一个高响应区域,即更局部细节的高级语义信息。
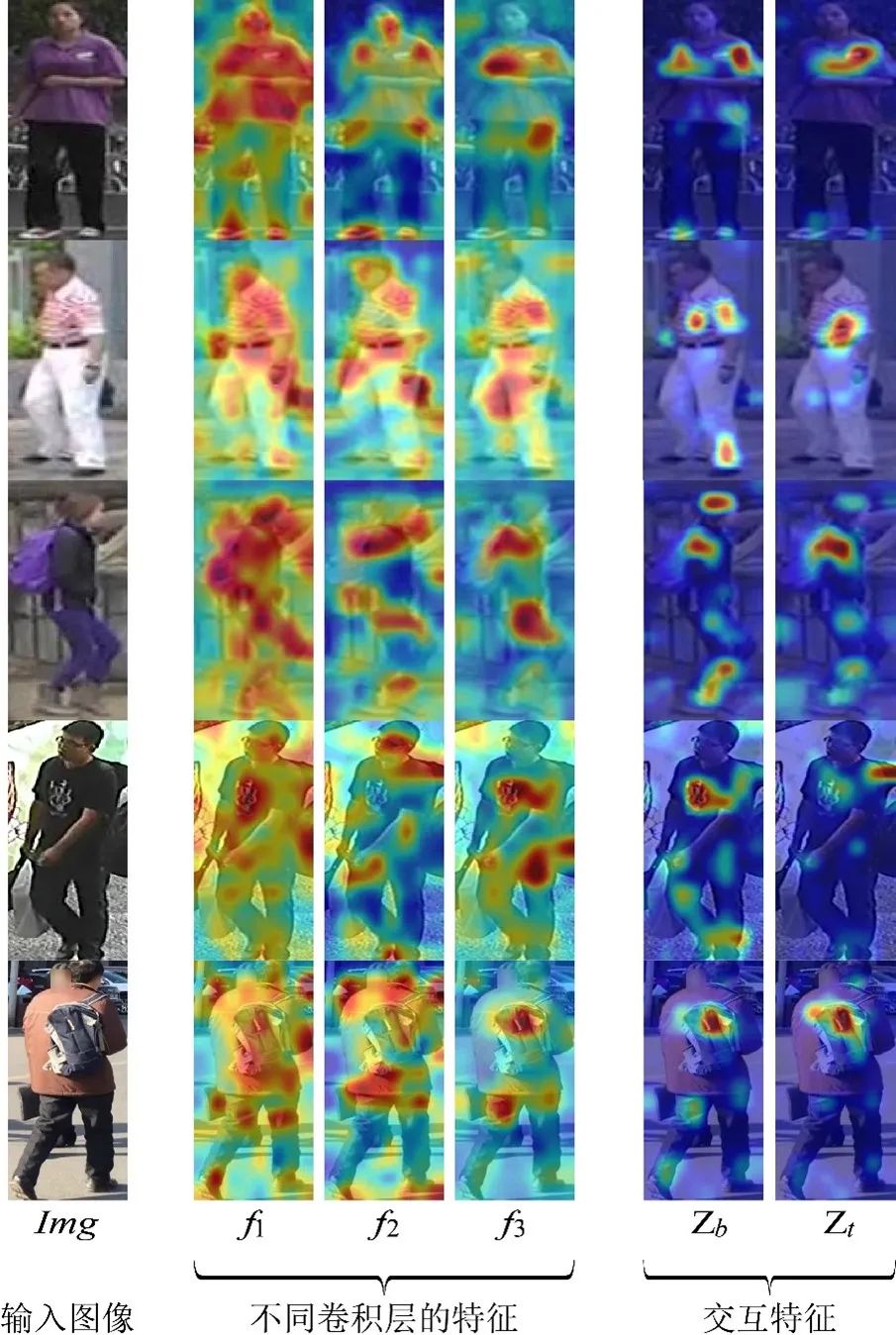
图2 卷积层特征响应的可视化结果展示。其中,,,表示不同层的卷积层特征,和分别表示自浅而深和自深而浅两个交互过程得到的特征。蓝色到红色表示特征响应程度从小到大。

编辑人:桑基韬、聂礼强

![[Android] 全套毕业论文写作指导 android电子市场(搭建环境+Galaxy S2模拟器全套+论文+代码+SVN)](https://static.kouhao8.com/sucaidashi/xkbb/41b11495e23c9df422ea269815e8a1ec.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)























相关资源