

SPSS Moeler 疑难解答专帖
发布于 2021-04-26 03:08 ,所属分类:知识学习综合资讯
虽然SPSS Modeler是一个非常易用的图形化界面工具,但在日常使用中,还是有一些朋友会遇到一些“疑难问题”,因此本篇文章就是对一些常见问题的解答。

#1系统问题#
1.1 为什么我在刚刚刚安装程序后,或者一段时间没有使用后重新使用,会发现出现一些如下的问题或错误:(1) 运行模型后提示如“javaXXXX错误”或“系统错误”
(2) 无法显示这个表(这个表可能是用更高级的版本创建)
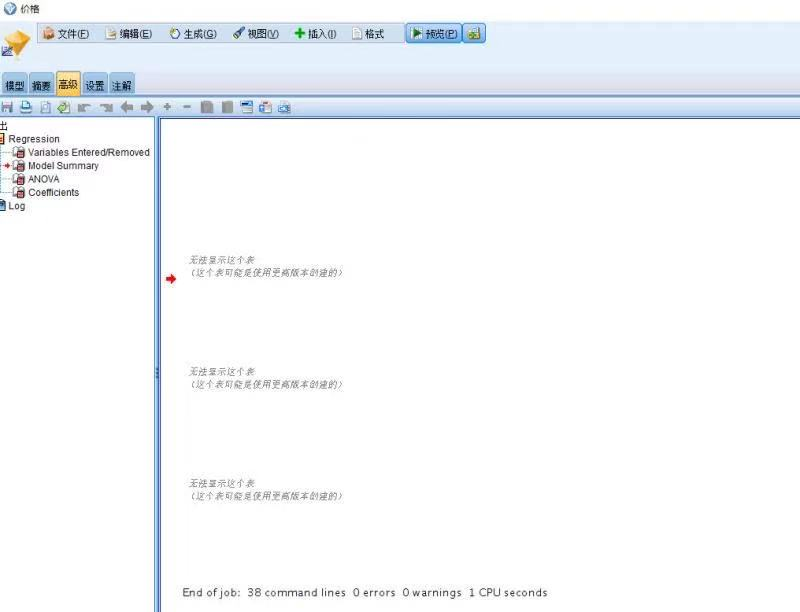
答: 这类问题一般可以通过重装解决,但是不一定需要重装,大家可以先执行如下步骤确认:
(1)运行demo程序,运行demo程序的目的是确认究竟是SPSS的程序问题,还是自己搭建的模型流问题;如何运行demo程序可以查看文章:
SPSS Modeler的Demo案例指南
(2)重启电脑、重启程序
(3)重装SPSS Modeler
#2数据相关问题#
2.1 为什么数据源和模型都是一样的,但是结果不一样?
答: 部分算法(如聚类、神经网络、抽样)由于具有一定的随机性,因此结果可能存在一定的差异,要想复现结果,需要进一步设定随机种子,关于随机种子的介绍可以参考如下文章:
结果复现的秘密|随机数和随机种子
2.2 我利用分区节点把训练集、测试集、验证集设定为划分6:3:1,但是最后的划分结果还是有差异?
答: Modeler的数据集划分由于是随机抽样划分的,因此最终划分结果与原始设定结果存在一定的偏差。但这个偏差的结果随着样本数量的增加会逐渐减少。对于小样本数据要进行划分,如果认为划分的偏差太大,可以修改随机种子进行重新划分。下图分别是对应10、100、1000以及10000个样本分别采用6:3:1的划分结果:
(1)10个样本(注:也可以通过调整随机种子已达到6:3:1的最终划分)

(2)100个样本

(3)1000个样本

(4)10000个样本

下图分别是
2.3 为什么我的数据集中,某些字段会被系统强制识别为“无类型”?
答 有些时候,当用户读取数据并对数据进行实例化后,会发现有些字段被强制设为“无类型”。如下所示,地区字段作为一个关键输入,在实例化前用户是把它设置为“分类”。但是在用户读取值,对数据进行实例化后却被SPSS Modeler强制设为“无类型”,
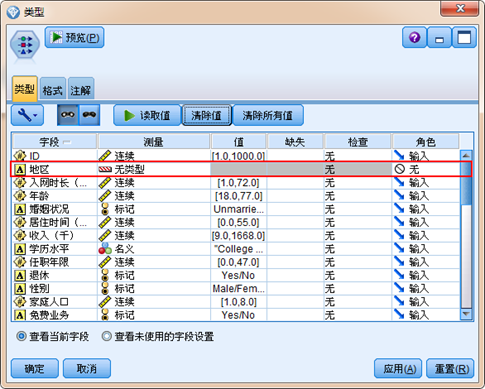
在SPSS Modeler中,分类型变量默认的最大集合大小为 250。即当某变量含有超过250个类别时,将被SPSS Modeler强制转为“无类型”。因此当某个变量取值数量超过250,但是用户又需要把它纳入模型,那么就需要更改名义字段的最大成员数。
如下图所示,该默认值可在菜单栏的【工具】→【流属性】→【选项】→【常规】中的名义字段的最大成员数中设置,当然也可以取消最大成员数限制,把选项前面的勾去掉即可。
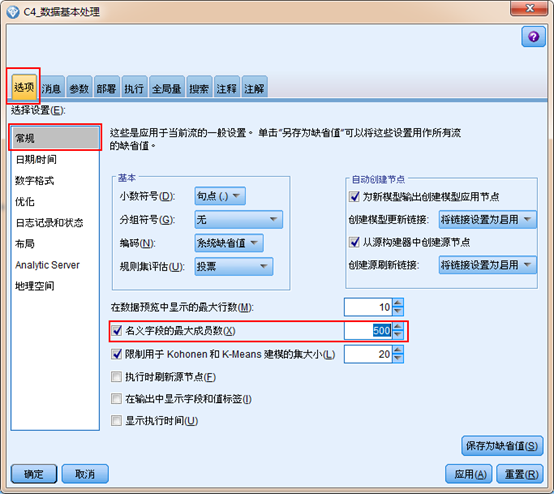
#3建模相关问题#
3.1 建立模型后,为什么打开模型没有结果,预测变量重要性显示不可用?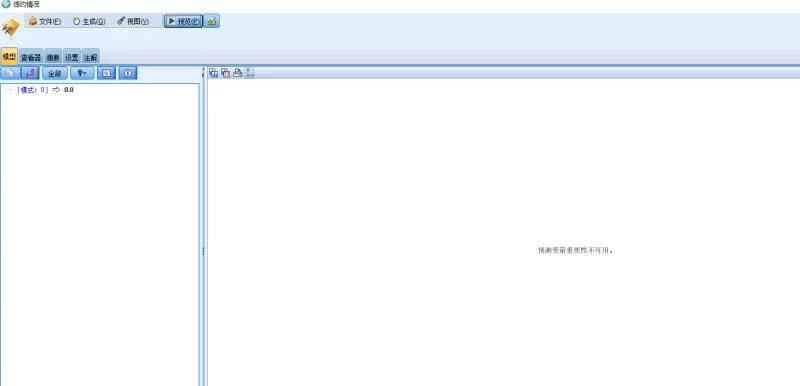
答 部分模型,虽然建立了模型但却是一个无效模型。如上图所示所构建的决策树模型,虽然表面上建立成功了,但是我们仔细观察所建立的决策树模型,会发现该模型把全部的数据样本都识别为类别为“0类别”,因此该模型是一个无效模型,也没有使用到任何的变量,因此预测变量重要性的结果也就不显示了。
那么为什么会出现这种情况呢? 这个问题可能是由于分类样本失衡,以及自变量分类效果不佳所导致的。举个例子,例如我有100个样本,其中有99个样本属于“类别0”,仅有1个样本属于“类别1”,那么我不需要任何的预测自变量,直接把所有样本都判定为“类别0”,那么我的模型也获得了99%的准确率了。
关于SPSS Modeler使用的更多疑问,欢迎在文末留言或咨询!
长篇干货写作不易,欢迎点击右下角的 在看 支持!关于本期主题,大家有什么想说的或者疑问,欢迎各位在文末评论留言。











![【定哥】高考历史专题解答之主观题技巧[百度网盘资源]](https://static.kouhao8.com/cunchu/cunchu7/2023-05-18/UpFile/defaultuploadfile/230505ml2/117-1.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)






![【高中英语听力】高三英语听力专练[百度网盘资源]](https://static.kouhao8.com/cunchu/cunchu7/2023-05-18/UpFile/defaultuploadfile/230425ml/139-1.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)





相关资源